A Dataset Showing a Century of Evolution in the Complexity of the United States Legal Code
Jan 6, 2026·,,,,,·
0 min read
Dawoon Jeong
James Holehouse
Jisung Yoon
Christopher P. Kempes
Geoffrey B. West
Hyejin Youn*
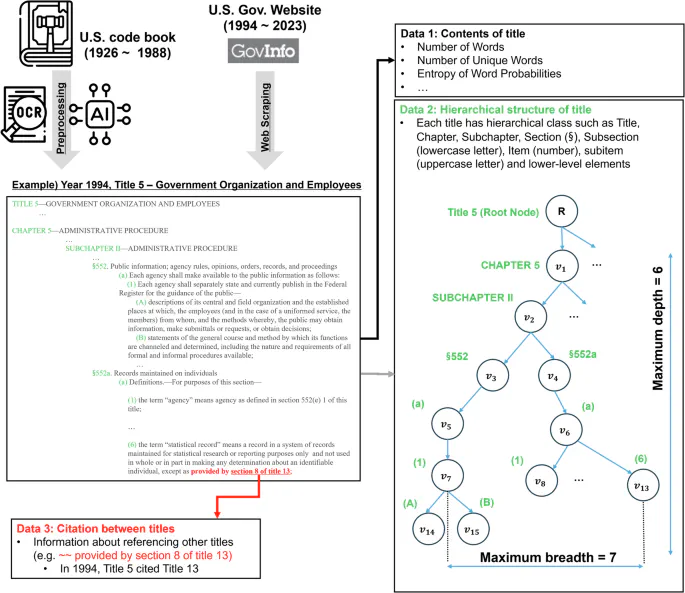 Figure 1, Jeong et al. (2026), Scientific Data
Figure 1, Jeong et al. (2026), Scientific DataAbstract
As societies confront increasingly complex regulatory demands in domains such as digital governance, climate policy, and public health, there is a pressing need to understand how legal systems evolve, where they concentrate regulatory attention, and how their institutional architectures shape capacity for adaptation. Yet, the long-term structural dynamics of law remain empirically underexplored. Here, we provide a quantitative analysis of the United States Code (U.S. Code), the primary compilation of federal statutory law in the United States, covering the entire history of the Code from 1926 to 2023. We include statistics related to the structural and linguistic complexity of the Code: word counts, vocabulary statistics, hierarchical organization (titles, chapters, sections, subsections), and cross-references among titles. Additionally, we make the generative AI method utilized to clean the old OCR versions of the U.S. Code publicly available. The dataset offers an empirical foundation for large-scale and long-term interdisciplinary analysis of the growth, reorganization, and internal logic of statutory systems. The dataset is released on GitHub with comprehensive documentation to support reuse across legal studies, data science, complexity research, and institutional analysis.
Type
Publication
In Scientific Data, 13, 13